Excel에서 문자열에서 숫자와 텍스트를 분할하는 방법
여러 번 분석을 위해 현장과 서버에서 혼합 데이터를 얻습니다. 이 데이터는 일반적으로 열이 숫자 및 텍스트와 혼합되어 더티입니다. 분석하기 전에 데이터 정리를 수행하면서 별도의 열에서 숫자와 텍스트를 분리합니다. 이 기사에서는 어떻게 할 수 있는지 알려 드리겠습니다.
시나리오 :
그래서 Exceltip.com의 한 친구가 댓글 섹션에서이 질문을했습니다. “Excel Formula를 사용하여 텍스트 앞과 텍스트 끝에 오는 숫자를 어떻게 구분합니까? 예 : 125EvenueStreet 및 LoveYou3000 등. ” 텍스트를 추출하기 위해 RIGHT, LEFT, MID 및 기타 텍스트 기능을 사용합니다. 추출 할 텍스트의 수만 알면됩니다. 그리고 여기서 우리는 먼저 똑같이 할 것입니다.
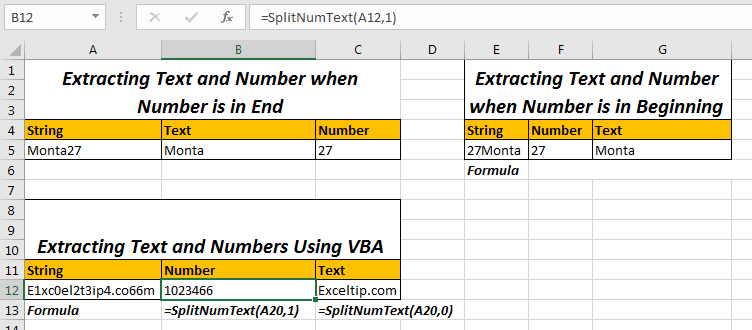
숫자가 문자열의 끝에있을 때 문자열에서 숫자와 텍스트 추출 위의 예를 들어이 시트를 준비했습니다. Cell A2에는 문자열이 있습니다. B2 셀에는 텍스트 부분이 필요하고 C2에는 숫자 부분이 필요합니다.

따라서 숫자가 시작되는 위치 만 알면됩니다. 그런 다음 Left 및 기타 기능을 사용합니다. 따라서 첫 번째 숫자의 위치를 얻으려면 다음 일반 공식을 사용합니다.
문자열에서 첫 번째 숫자의 위치를 가져 오는 일반 공식 :
=MIN(SEARCH({0,1,2,3,4,5,6,7,8,9},String_Ref&"0123456789")
이것은 첫 번째 숫자의 위치를 반환합니다.
위의 예에서는이 수식을 모든 셀에 작성하십시오.
=MIN(SEARCH({0,1,2,3,4,5,6,7,8,9},A5&"0123456789"))
텍스트 부분 추출
Text의 15 번째 위치에있는 첫 번째 숫자로 15를 반환합니다. 나중에 설명하겠습니다.
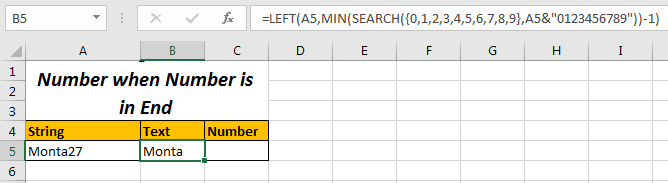
이제 텍스트를 얻으려면 왼쪽에서 문자열에서 15-1 문자를 가져 오면됩니다. 그래서 우리는`link : / excel-text-extract-text-from-a-string-in-excel-using-excels-left-and-right-function [LEFT function to extract text.]`
왼쪽에서 텍스트를 추출하는 수식
=LEFT(A5,MIN(SEARCH({0,1,2,3,4,5,6,7,8,9},A5&"0123456789"))-1)
여기서는 MIN (link : / text-excel-search-function [SEARCH](\ {0,1,2,3,4,5,6,7,8,9)이 반환 한 숫자에서 1을 뺍니다. }, A5 & “0123456789”)).
번호 부분 추출
이제 숫자를 얻으려면 발견 된 첫 번째 숫자에서 숫자 문자를 가져 오면됩니다. 그래서 우리는 문자열의 총 길이를 계산하고 찾은 첫 번째 숫자의 위치를 빼고 여기에 1을 더합니다. 단순한. 예, 복잡하게 들리지만 간단합니다.
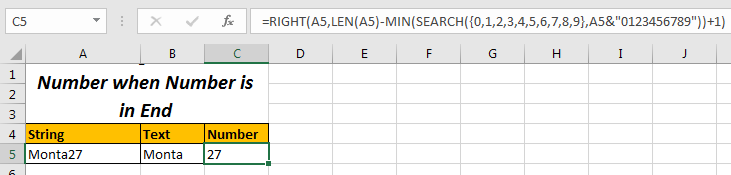
오른쪽에서 숫자를 추출하는 공식
=RIGHT(A5,LEN(A5)-MIN(SEARCH({0,1,2,3,4,5,6,7,8,9},A5&"0123456789"))+1)
여기서 우리는`link : / len-functio [LEN function]을 사용하여 문자열의 전체 길이를 구한 다음 처음 찾은 숫자의 위치를 뺀 다음 여기에 1을 더했습니다. 이것은 우리에게 총 숫자를 제공합니다. 여기에서 //excel-text/extract-text-from-a-string-in-excel-using-excels-left-and-right-function.html[Excel의 LEFT 및 RIGHT 함수를 사용하여 텍스트 추출]`에 대해 자세히 알아보세요.
따라서 LEFT 및 RIGHT 기능 부분은 간단합니다. Tricky 부분은 MIN과 SEARCH 부분으로 처음 발견 된 숫자의 위치를 알려줍니다. 이해합시다.
작동 원리
LEFT 및 RIGHT 함수가 어떻게 작동하는지 알고 있습니다. 발견 된 첫 번째 숫자의 위치를 가져 오는이 공식의 주요 부분을 살펴 보겠습니다.
MIN (link : / text-excel-search-function [SEARCH](\ {0,1,2,3,4,5,6,7,8,9}, String & “0123456789”)
`link : / text-excel-search-function [SEARCH function]`은 문자열에서 텍스트의 위치를 반환합니다.
SEARCH ( ‘text’, ‘string’) 함수는 두 개의 인수, 먼저 텍스트를받습니다. 두 번째는 검색하려는 문자열입니다.
여기 SEARCH의 텍스트 위치에는 0에서 9까지의 숫자 배열이 있습니다. 그리고 문자열 위치에는 “로 연결된 문자열이 있습니다. 0123456789 “는 & * 연산자를 사용합니다. 이유는 무엇입니까?
-
배열 \ {0,1,2,3,4,5,6,7,8,9}의 각 요소는 주어진 문자열에서 검색되고 배열의 동일한 인덱스에있는 배열 형식 문자열의 위치를 반환합니다.
-
값이 없으면 오류가 발생하므로 모든 수식에 오류가 발생합니다. 이를 방지하기 위해 텍스트에서 숫자 “0123456789”를 연결하여 항상 문자열에서 각 숫자를 찾습니다.
이 숫자는 끝에 있습니다. 따라서 문제가 발생하지 않습니다.
-
이제 MIN 함수는 SEARCH 함수가 반환 한 배열에서 가장 작은 값을 반환합니다. 이 가장 작은 값은 문자열의 첫 번째 숫자가됩니다. 이제이 NUMBER 및 LEFT 및 RIGHT 함수를 사용하여 텍스트와 문자열 부분을 분할 할 수 있습니다.
우리의 예를 살펴 보겠습니다. A5에는 거리 이름과 집 번호가있는 문자열이 있습니다. 우리는 그것들을 다른 세포에서 분리해야합니다.
먼저 문자열에서 첫 번째 숫자의 위치를 어떻게 얻었는지 살펴 보겠습니다.
MIN (SEARCH (\ {0,1,2,3,4,5,6,7,8,9}, A5 & “0123456789”)) : 이것은 MIN (SEARCH (\ {0,1,2, 3,4,5,6,7,8,9},”Monta270123456789 *”))
이제 내가 설명했듯이 검색은 Monta270123456789의 배열 \ {0,1,2,3,4,5,6,7,8,9}에서 각 숫자를 검색하고 배열 형식으로 해당 위치를 반환합니다. 반환 된 배열은 \ {8,9,6,11,12,13,14,7,16,17}입니다. 어떻게?
0은 문자열에서 검색됩니다. 8 위치에 있습니다. 따라서 첫 번째 요소는 8입니다. 원본 텍스트의 길이는 7 자에 불과합니다. 그것을 얻으십시오. 0은 Monta27의 일부가 아닙니다. 다음 1은 문자열에서 검색되고 원래 문자열의 일부가 아니므로 위치 9를 얻습니다.
다음 2 개가 검색됩니다. 원래 문자열의 일부이므로 색인을 6으로 얻습니다.
마찬가지로 각 요소는 특정 위치에서 발견됩니다.
-
이제이 배열은`link : / statistical-excel-min-function [MIN function]`에 MIN (\ {8,9,6,11,12,13,14,7,16,17})로 전달됩니다. MIN은 원래 텍스트에서 찾은 첫 번째 숫자의 위치 인 6을 반환합니다.
그리고 그 이후의 이야기는 아주 간단합니다. 이 숫자는 LEFT 및 RIGHT 함수를 사용하여 텍스트와 숫자를 추출하는 데 사용됩니다.
숫자가 문자열의 시작에있을 때 문자열에서 숫자와 텍스트를 추출합니다. 위의 예에서 숫자는 문자열의 끝에있었습니다. 숫자가 처음에있을 때 숫자와 텍스트를 어떻게 추출합니까?
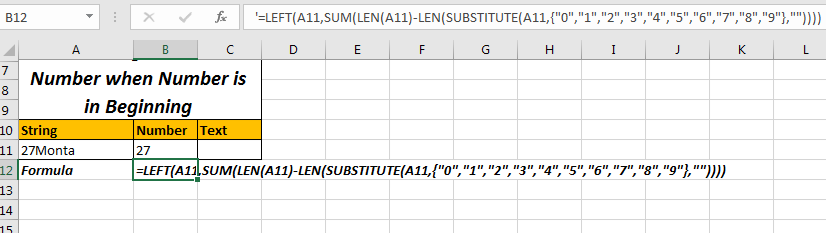
위와 비슷한 테이블을 준비했습니다. 처음에는 숫자 만 있습니다.
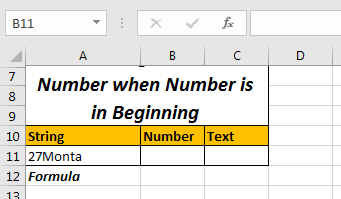
여기서 우리는 다른 기술을 사용할 것입니다. 숫자의 길이 (여기서는 2)를 계산하고 문자열 왼쪽에서 해당 문자 수를 추출합니다.
따라서 방법은 = LEFT (문자열, 숫자 개수)
문자 수를 계산하는 것이 공식입니다.
숫자 수를 계산하는 일반 공식 :
=SUM(LEN(string)-LEN(SUBSTITUTE(string,{"0","1","2","3","4","5","6","7","8","9"},""))
여기서 **`link : / excel-text-formulas-excel-substitute-function [SUBSTITUTE function]`은 찾은 각 숫자를“”(공백)로 바꿉니다. 숫자가 대체되고 새로운 문자열이 배열에 추가되면 다른 현명한 원래 문자열이 배열에 추가됩니다. 이런 식으로 10 개의 문자열 배열을 갖게됩니다.
이제 LEN 함수는 해당 문자열 배열의 문자 길이를 반환합니다.
그런 다음 원래 문자열의 길이에서 SUBSTITUTE 함수가 반환 한 각 문자열의 길이를 뺍니다. 이것은 다시 배열을 반환합니다.
이제 SUM은이 모든 숫자를 더합니다. 이것은 문자열의 숫자 개수입니다.
문자열에서 숫자 부분 추출
이제 문자열의 숫자 길이를 알았으므로이 함수를 LEFT로 대체합니다.
문자열이 A11이므로 다음과 같습니다.
왼쪽에서 숫자를 추출하는 공식
=LEFT(A11,SUM(LEN(A11)-LEN(SUBSTITUTE(A11,{"0","1","2","3","4","5","6","7","8","9"},""))))
문자열에서 텍스트 부분 추출
숫자의 수를 알기 때문에 문자열의 총 길이에서 빼서 문자열의 숫자 알파벳을 얻은 다음 right 함수를 사용하여 문자열 오른쪽에서 해당 문자 수를 추출 할 수 있습니다.
오른쪽에서 텍스트를 추출하는 수식
=RIGHT(A11,LEN(A2)-SUM(LEN(A11)-LEN(SUBSTITUTE(A11,{"0","1","2","3","4","5","6","7","8","9"},""))))

작동 원리
두 수식의 주요 부분은 SUM (LEN (A11) -LEN (SUBSTITUTE (A11, \ { “0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”}, “”)))
숫자의 첫 번째 발생을 계산합니다. 이것을 찾은 후에 만 LEFT 함수를 사용하여 텍스트와 숫자를 분할 할 수 있습니다. 그래서 이것을 이해합시다.
-
SUBSTITUTE (A11, \ { “0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”}, ” “) :
이 부분은이 숫자를 아무것도 / 공백 (“”)으로 대체 한 후 A11의 문자열 배열을 반환합니다. 27Monta의 경우 \ { “27Monta”, “27Monta”, “7Monta”, “27Monta”, “27Monta”, “27Monta”, “27Monta”, “2Monta”, “27Monta”, “27Monta”}를 반환합니다.
LEN (SUBSTITUTE (A11, \ { “0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”}, ” “)) :
이제 SUBSTITUTE 부분이 LEN 함수로 래핑됩니다. 이것은 SUBSTITUTE 함수에 의해 반환 된 배열의 텍스트 길이를 반환합니다. 결과적으로 \ {7,7,6,7,7,7,7,6,7,7}이됩니다.
LEN (A11) -LEN (SUBSTITUTE (A11, \ { “0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, ” 9 “},” “)) :
여기에서는 실제 문자열의 길이에서 위 부분에서 반환 된 각 숫자를 뺍니다. 원본 텍스트의 길이는 7입니다. 따라서 \ {7-7,7-7,7-6, ….}이됩니다. 마지막으로 \ {0,0,1,0,0,0,0,1,0,0}이 있습니다.
SUM (LEN (A11) -LEN (SUBSTITUTE (A11, \ { “0”, “1”, “2”, “3”, “4”, “5”, “6”, “7”, “8” , “9”}, “”))) :
여기서는 SUM을 사용하여 함수의 위 부분에서 반환 된 배열을 합산했습니다.
이것은 2를 줄 것입니다. 이것은 문자열의 숫자 수입니다.
이제 이것을 사용하여 텍스트와 숫자를 추출하고 다른 셀로 분할 할 수 있습니다. 이 방법은 숫자가 시작일 때와 끝날 때 두 유형 텍스트 모두에서 작동합니다. LEFT 및 RIGHT 기능을 적절하게 활용하기 만하면됩니다.
SplitNumText 함수를 사용하여 문자열에서 숫자와 텍스트 분할
위의 방법은 약간 복잡하며 텍스트와 숫자가 혼합 된 경우 유용하지 않습니다. 텍스트와 숫자를 분할하려면이 사용자 정의 함수를 사용하십시오.
구문 :
=SplitNumText(string, op)
문자열 : 분할하려는 문자열입니다.
Op : 부울입니다. 텍스트 부분을 얻으려면 0 또는 false를 전달하십시오. 숫자 부분의 경우 true 또는 0보다 큰 숫자를 전달합니다.
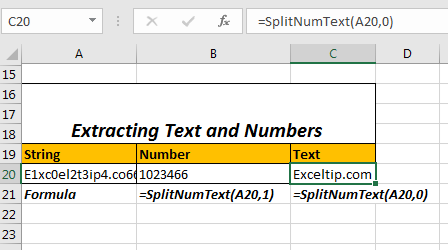
예를 들어, 문자열이 A20이면
문자열에서 숫자를 추출하는 공식은 다음과 같습니다.
=SplitNumText(A20,1)
그리고
문자열에서 텍스트를 추출하는 공식은 다음과 같습니다.
=SplitNumText(A20,0)
위의 수식이 작동하도록 VBA 모듈의 코드 아래에 복사하십시오.
Function SplitNumText(str As String, op As Boolean) num = "" txt = "" For i = 1 To Len(str) If IsNumeric(Mid(str, i, 1)) Then num = num & Mid(str, i, 1) Else txt = txt & Mid(str, i, 1) End If Next i If op = True Then SplitNumText = num Else SplitNumText = txt End If End Function
이 코드는 단순히 숫자인지 아닌지 문자열의 각 문자를 확인합니다. 숫자이면 txt 변수의 num 변수에 저장됩니다. 사용자가 op에 대해 true를 전달하면 num이 반환되고 txt가 반환됩니다.
이것은 내 생각에 문자열에서 숫자와 텍스트를 분리하는 가장 좋은 방법입니다.
원하는 경우 여기에서 통합 문서를 다운로드 할 수 있습니다.
예, 여러분, 이것은 다른 셀에서 텍스트와 숫자를 분할하는 방법입니다. 아래 의견 섹션에 의문 사항이나 더 나은 해결책이 있으면 알려주십시오. 남자들과 상호 작용하는 것은 항상 재미 있습니다.
작업 파일을 다운로드하려면 아래 링크를 클릭하십시오.
`link : /wp-content-uploads-2019-11-Split-Number-and-Text-from-A-Cell.xls [__ Split Number and Text from A Cell]
관련 기사 :
link : / mail-send-and-receive-in-vba-how-to-extract-domain-name-from-email-in-excel [Excel의 이메일에서 도메인 이름을 추출하는 방법]
link : / excel-text-formulas-split-numbers-and-text-from-string-in-excel [Excel의 문자열에서 숫자와 텍스트 분할]
인기 기사 :
link : / keyboard-formula-shortcuts-50-excel-shortcuts-to-increase-your-productivity [50 Excel 단축키로 생산성 향상]
link : / formulas-and-functions-introduction-of-vlookup-function [Excel의 VLOOKUP 함수]
link : / tips-countif-in-microsoft-excel [Excel 2016의 COUNTIF]
link : / excel-formula-and-function-excel-sumif-function [Excel에서 SUMIF 함수 사용 방법]