어떻게 Excel에서 상관 계수를 찾기
상관 계수는 무엇입니까?
데이터 세트의 상관 계수는 두 변수가 서로 얼마나 밀접하게 관련되어 있는지를 나타내는 통계 수치입니다. 두 변수 (x와 y) 사이의 관계에 대한 백분율이라고 할 수 있습니다. 100 %보다 크고 -100 %보다 작을 수 없습니다.
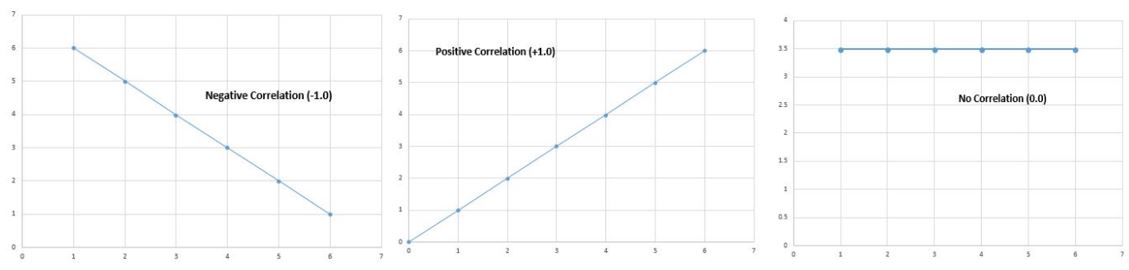
상관 계수는 -1.0에서 +1.0 사이입니다.
음의 상관 계수는 하나의 변수가 증가하면 다른 변수는 감소 함을 알려줍니다. -1.0의 상관 관계는 완벽한 음의 상관 관계입니다. 이것은 x가 1 단위 증가하면 y는 1 단위 감소 함을 의미합니다.
양의 상관 계수는 한 변수의 값이 증가하면 다른 변수의 값도 증가한다는 것을 의미하며, 이는 x가 1 단위 증가하면 y도 1 단위 증가 함을 의미합니다.
0의 상관 관계는 두 변수간에 관계가 없다는 것을 의미합니다.
상관 계수의 수학 공식은 다음과 같습니다.
Coveriance ~ xy ~ / (Std ~ x ~ * Std ~ y ~)
Coveriance ~ xy ~는 데이터 세트의 공분산 (표본 또는 모집단)입니다.
Std ~ x ~ = Xs의 표준 편차 (표본 또는 모집단)입니다.
Std ~ y = ~ Ys의 표준 편차 (표본 또는 모집단)입니다.
Excel에서 상관 계수를 계산하는 방법?
Excel에서 상관 관계를 계산해야하는 경우 수학 공식을 사용할 필요가 없습니다. 이러한 방법을 사용할 수 있습니다. COREL 함수를 사용하여 상관 계수 계산.
-
Analysis Toolpak을 사용하여 상관 계수 계산.
Excel에서 상관 계수를 계산하는 노하우의 예를 살펴 보겠습니다.
Excel에서 상관 계수 계산의 예 여기에 샘플 데이터 세트가 있습니다. 범위 A2 : A7에 xs가 있고 B2 : B7에 ys가 있습니다.
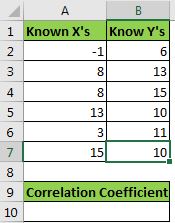
xs와 ys의 상관 계수를 계산해야합니다.
Excel CORREL 함수 사용
CORREL 함수의 구문 :
|
=CORREL(array1,array2) |
array1 : * 첫 번째 값 집합 (xs)
array2 : * 두 번째 값 집합 (ys)입니다.
참고 : 배열 1과 배열 2는 크기가 같아야합니다.
상관 계수를 얻기 위해 CORREL 함수를 사용합시다. 이 공식을 A10에 작성하십시오.
|
=CORREL(A2:A7,B2:B7) |
x와 y 사이의 상관 관계는 0.356448487 또는 36 %입니다.
Excel 분석 도구 사용
분석 툴팩을 사용하여 상관 관계를 계산하려면 다음 단계를 따르십시오.
-
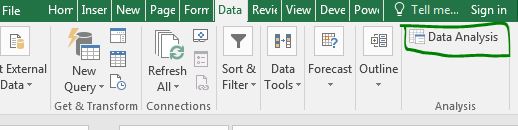
리본의 데이터 탭으로 이동합니다. 가장 왼쪽 구석에 데이터 분석 옵션이 있습니다. 그것을 클릭하십시오. 표시되지 않으면 먼저`link : / tips-the-analysis-toolpak-in-excel [분석 도구 설치]`가 필요합니다.
-
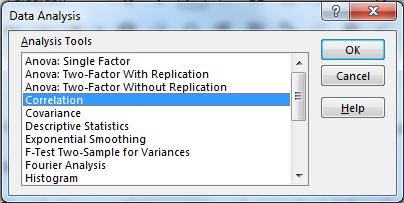
사용 가능한 옵션에서 상관 관계를 선택합니다.
-
입력 범위를 A2 : B7로 선택하십시오. 출력을 보려는 출력 범위를 선택하십시오.
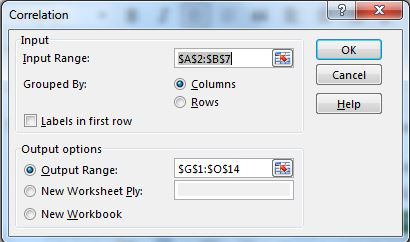
-
확인 버튼을 누르십시오. 원하는 범위에 상관 계수가 있습니다. CORREL 함수에서 반환 한 것과 정확히 동일한 값입니다.
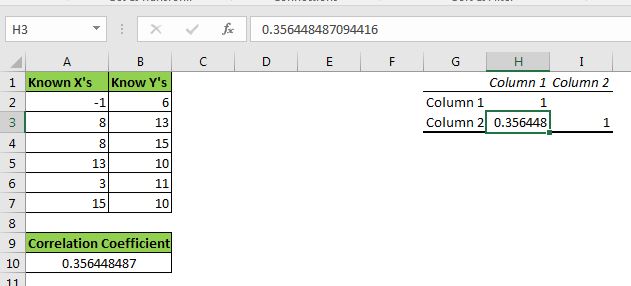 How correlation is being calculated?* To understand how we are getting this value, we need to find it manually. This will clear our doubts.
How correlation is being calculated?* To understand how we are getting this value, we need to find it manually. This will clear our doubts.
우리가 알고 있듯이 상관 계수는 다음과 같습니다.
Coveriance ~ xy ~ / (Std ~ x ~ * Std ~ y ~)
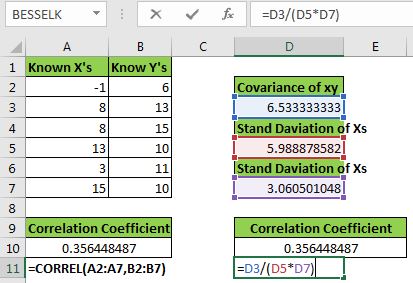
먼저 공분산을 계산해야합니다. Excel의 COVERIACE.S 함수를 사용하여 계산할 수 있습니다.
|
=COVARIANCE.S(A2:A7,B2:B7) |
다음으로,link : / statistical-formulas-how-to-use-stdev-s-function-in-excel [STDEV.S]
를 사용하여 x와 y의 표준 편차를 계산해 봅시다. 함수.
|
= |
|
= |
이제 D10 셀에이 수식을 작성합니다.
|
=D3/(D5*D7) |
이것은 = Covariance ~ xy ~ / (Std ~ x ~ * Std ~ y ~)와 같습니다. CORREL 함수에 의해 주어진 것과 똑같은 값을 얻는 것을 볼 수 있습니다. 이제 Excel에서 상관 계수를 어떻게 도출했는지 알게되었습니다.
참고 : * 위 예에서는 COVARIANCE.S (샘플의 공분산) 및`link : / statistical-formulas-how-to-use-stdev-s-function-in-excel [STDEV.S]를 사용했습니다. `
(샘플의 표준 편차). COVARIANCE.P 및`link : / statistical-formulas-how-to-use-excel-stdev-p-function [STDEV.P]`을 사용하는 경우 상관 계수는 동일합니다. 둘 다 동일한 범주에 속하면 차이가 없습니다. COVARIANCE.S (샘플의 공분산) 및`link : / statistical-formulas-how-to-use-excel-stdev-p-function [STDEV.P]`을 사용하는 경우
(인구의 표준 편차) 그러면 결과가 다르고 부정확 할 것입니다 .__ 그러니 여러분, 이것이 엑셀에서 상관 계수를 계산하는 방법입니다. 상관 계수를 설명하기에 충분히 설명이 되었기를 바랍니다. 이제 Excel에서 고유 한 상관 계수 계산기를 만들 수 있습니다.
관련 기사 :
link : / statistical-formulas-calculate-intercept-in-excel [Excel에서 INTERCEPT 계산]
link : / statistical-formulas-calculating-slope-in-excel [Excel에서 SLOPE 계산]
link : / tips-regression-data-analysis-tool [Excel의 회귀]
link : / statistical-formulas-how-to-create-standard-deviation-graph-in-excel [표준 편차 그래프 생성 방법]
link : / tips-descriptive-statistics [Microsoft Excel 2016의 기술 통계]
link : / statistical-formulas-how-to-use-excel-normdist-function [Excel NORMDIST 함수 사용 방법]
link : / tips-how-to-create-a-pareto-chart-in-microsoft-excel [파레토 차트 및 분석]
인기 기사 :
link : / keyboard-formula-shortcuts-50-excel-shortcuts-to-increase-your-productivity [50 Excel 단축키로 생산성 향상]
link : / formulas-and-functions-introduction-of-vlookup-function [Excel의 VLOOKUP 함수]
link : / tips-countif-in-microsoft-excel [Excel 2016의 COUNTIF]
link : / excel-formula-and-function-excel-sumif-function [Excel에서 SUMIF 함수 사용 방법]