어떻게 Excel에서 계산 분산에
==== 분산이란 무엇입니까? 데이터의 분산을 사용하여 시리즈의 미래 가치 범위를 추정합니다. 분산은 데이터 세트의 평균에서 얼마나 많은 데이터가 달라질 수 있는지를 나타냅니다. 분산은 종종 오류 값이라고합니다. 가장 신뢰할 수있는 통계는 아니며 미래 가치를 예측하는 데 단독으로 사용하지 않습니다.
수학적으로 말하면 분산은 데이터 평균과 데이터 포인트의 차이 제곱의 평균입니다. 분산은`link : / excel-financial-formulas-how-to-calculate-standard-deviation-in-excel [표준 편차]`의 제곱 값입니다. 다음은 두 가지 분산 공식입니다.
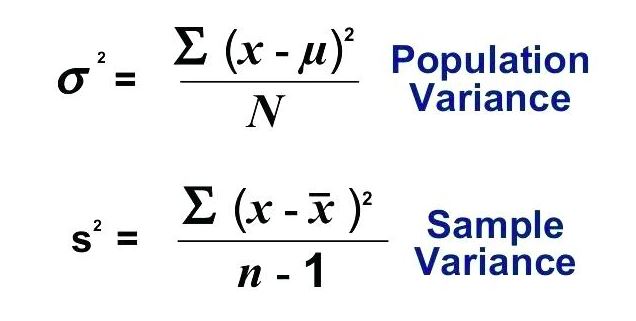
Excel에서 분산을 계산하기 위해 이러한 수식을 사용할 필요가 없습니다.
Excel에는이를 수행하는 두 가지 수식 VAR.P 및 VAR.S가 있습니다. Excel에서 분산을 계산하는 방법을 알고 싶다면 아래 설명 된 수식을 사용하십시오. 분산이 무엇이며 언제 어떤 분산 공식을 사용해야하는지 알고 싶다면 전체 기사를 읽어보십시오.
=== Excel에서 분산을 찾는 방법은 무엇입니까?
예를 들어 보겠습니다.
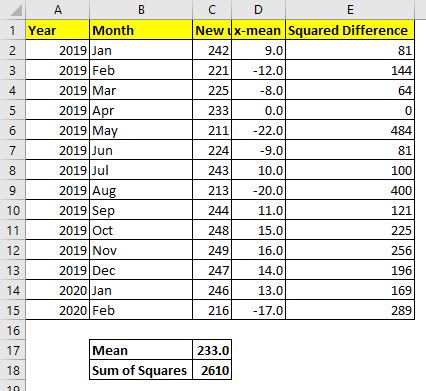
저는 2019 년 1 월에 제 웹 사이트를 시작했습니다. 여기 제 웹 사이트에 매달 가입 한 신규 사용자 데이터가 있습니다. 이 데이터의 분산을 알고 싶습니다.
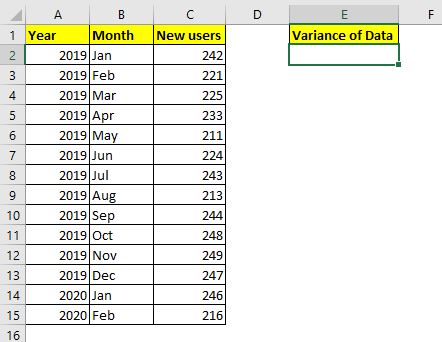
이것은 완전한 데이터입니다. 완전한 데이터 (전체 모집단)를 캡처 할 때
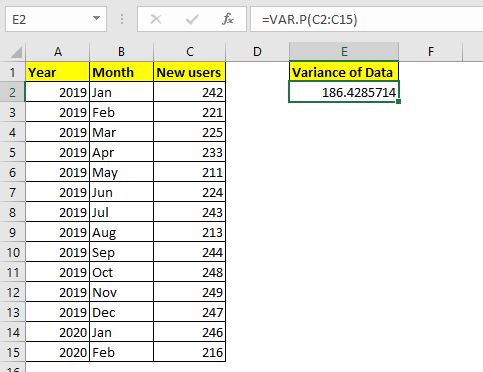
인구의 분산을 계산합니다 (이유는이 글의 뒷부분에서 설명하겠습니다). 모집단 분산을 계산하는 Excel 함수는`link : / statistical-formulas-how-to-use-var-p-function-in-excel [VAR.P]`입니다.
VAR.P의 구문은
=VAR.P(number1,[number2],...)
숫자 1, 숫자 2, … : 분산을 계산하려는 숫자입니다.
첫 번째 숫자는 필수입니다.
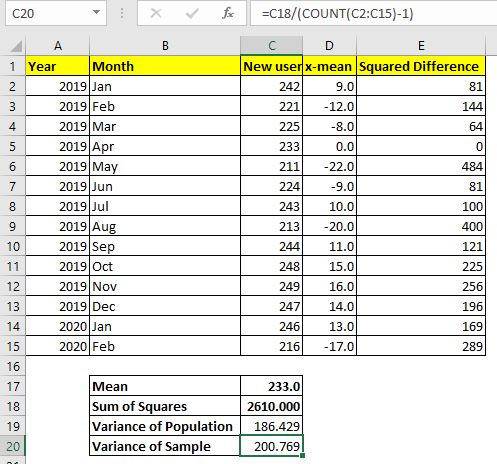
이 공식을 사용하여 데이터의 분산을 계산해 봅시다. C2 : C15 셀에 데이터가 있습니다. 따라서 공식은 다음과 같습니다.
|
= |
이렇게하면 186.4285714 값이 반환되며, 이는 데이터를 고려할 때 상당히 큰 분산입니다.
내 웹 사이트가 2019 년 1 월부터 시작되었으므로 모든 데이터를 가지고 있습니다.
오래 전에 웹 사이트를 시작했지만 보유한 데이터가 2019 년 1 월부터 2020 년 2 월까지라고 가정합니다. 완전한 데이터가 없습니다. 그러면 샘플 데이터 일뿐입니다. 이 경우 VAR.P를 사용하지 않고 대신 VAR.S 함수를 사용하여 분산을 계산합니다.
|
=VAR.S(C2:C15) |
VAR.S 함수는 VAR.P보다 큰 분산을 반환합니다. 200.7692308을 반환합니다.
=== Excel에서 분산은 어떻게 수동으로 계산됩니까? 예, 이것이 Excel에서 분산을 계산하는 방법입니다. 그러나 이러한 분산 함수는 이러한 숫자를 어떻게 계산합니까? 알고 있다면이 숫자를 더 많이 이해하고 현명하게 사용할 수 있습니다. 그렇지 않으면이 숫자는 난수 일뿐입니다. 이를 이해하려면 분산을 수동으로 계산해야합니다.
=== Excel에서 수동으로 인구 분산 계산
위의 예에서 사용한 것과 동일한 데이터를 사용합니다. 인구 분산의 수학 공식은 다음과 같습니다.
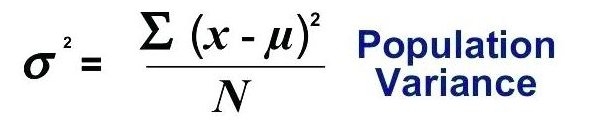
분산을 계산하려면 데이터의 평균 (AVERAGE), 평균과 각 값의 차이를 계산하고 합산 한 다음 마지막으로 그 합계를 총 관측 수로 나눕니다.
=== 1 단계. 데이터 평균 계산
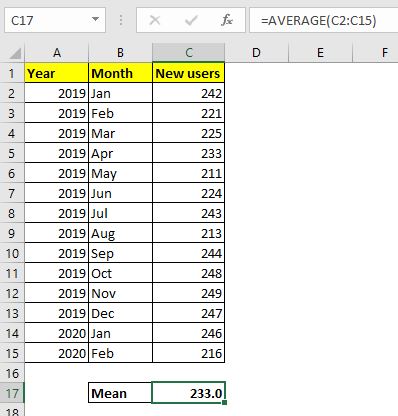
Excel에서 데이터의`link : / statistical-formulas-how-to-calculate-mean-in-excel [calculate mean]`을 사용하려면`link : / tips-average-function-in-excel [AVERAGE function]`을 사용합니다. .
이 수식을 C17 셀 (또는 원하는 위치)에서 사용하십시오.
|
= |
233.0을 반환합니다.
=== 2 단계 : 평균에서 각 데이터 포인트의 차이 찾기
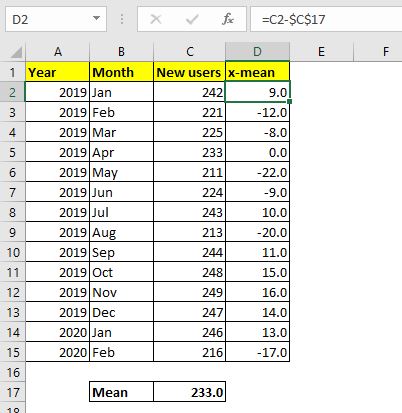
이제 셀 D2로 이동하여 C2 (x)에서 평균 (C17)을 뺍니다. D2에서이 공식을 사용하여 D15로 드래그합니다.
|
=C2-$C$17 |
=== 3 단계 : 각 차이를 조사합니다.
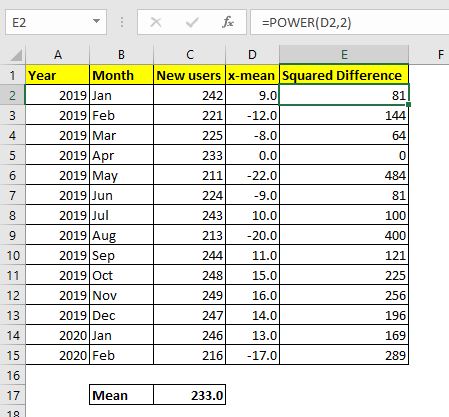
이제 우리가 얻은 각 차이를 제곱해야합니다. E2 셀에 아래 수식을 작성하고 E15로 드래그합니다.
|
= |
=== 4 단계 : 제곱합
이제 우리는 이러한 제곱 차이를 합산해야합니다. 따라서 C18 셀에서 다음 공식을 사용하십시오.
|
= |
=== 마지막 단계 : 제곱합을 관측치 수로 나눕니다.
14 개의 관찰이 있습니다. 원하는 경우 COUNT 함수를 사용하여 계산할 수 있습니다.
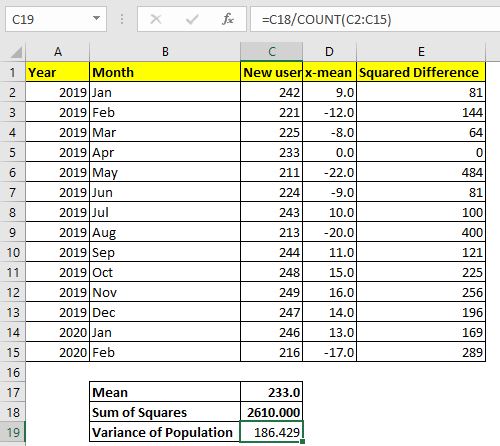
모집단의 분산을 계산하려면 셀 C19에서이 공식을 사용합니다.
|
=C18/COUNT(C2:C15) |
위의 Excel 분산 수식 VAR.P에서 반환 한 분산과 정확히 동일한 186.429 … 값을 반환합니다.
이제 Excel에서 모집단 분산을 수동으로 계산하는 방법을 알았으므로 실제 분석에서 사용하는 방법을 알 수 있습니다.
=== Excel에서 샘플의 분산을 수동으로 계산
대부분의 경우 분석을 위해 모든 데이터를 캡처하는 것은 불가능합니다. 일반적으로 데이터에서 임의의 샘플을 선택하고 분석하여 데이터의 특성을 해석합니다. 이 경우 모집단 분산을 사용하면 파괴 분석이 될 수 있습니다. 안전을 위해 표본 분산 공식을 사용합니다. 표본 분산의 공식은 다음과 같습니다.
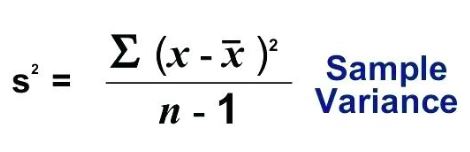
표본 분산과 모집단 분산의 유일한 차이점은 분모입니다. 표본 분산에서 관측치 수 (n-1)에서 1을 뺍니다. 이를 편향되지 않은 분석이라고합니다. 이렇게하면 데이터가 과소 평가되지 않고 가능한 오류 범위가 약간 더 넓어집니다.
Excel에서 샘플의 분산을 수동으로 계산하려면 모집단 분산의 1-4 단계를 반복해야합니다. 마지막 단계에서 아래 공식을 사용하십시오.
|
=C18/(COUNT(C2:C15)-1) |
200.769를 반환합니다. 이것은 VAR.S 함수가 반환하는 분산과 정확히 동일합니다. 예측 오류 가능성을 줄이기 위해 VAR.P보다 더 큰 오류 범위가 필요합니다.
데이터의 분산은 예측을 위해 신뢰할 수있는 것이 아닙니다. 예측 오류 가능성을 최소화하기 위해 분산의 제곱근 및 기타 많은 통계 인`link : / excel-financial-formulas-how-to-calculate-standard-deviation-in-excel [calculate standard 편차]`가 있습니다.
예 여러분, 이것이 엑셀의 분산을 계산하는 방법입니다. 설명적이고 도움이 되었기를 바랍니다. Excel 또는 기타 통계의이 차이에 대해 의심이가는 경우 댓글 섹션은 모두 귀하의 것입니다.
관련 기사
link : / excel-financial-formulas-how-to-calculate-standard-deviation-in-excel [Excel에서 표준 편차를 계산하는 방법]: 표준 편차를 계산하기 위해 여러 공식이 있습니다. 표준 편차는 단순히 분산의 제곱근입니다. 분산보다 데이터에 대해 더 많이 알려줍니다.
link : / statistical-formulas-how-to-use-var-p-function-in-excel [Excel에서 VAR.P 함수를 사용하는 방법]: VAR을 사용하여 Excel에서 모집단 데이터 수의 분산을 계산합니다. .P 함수`link : / statistical-formulas-how-to-use-excel-stdev-p-function : 다음을 사용하여 Excel에서 모집단 데이터 수에 대한 표준 편차를 계산합니다. the VAR.P function`link : / database-formulas-how-to-use-the-dstdevp-function-in-excel [How to use the DSTDEVP function in Excel]: 다음을 갖는 샘플 데이터 숫자에 대한 표준 편차를 계산합니다. DSTDEVP 함수`link : / statistical-formulas-excel-var-function [Excel에서 VAR 함수 사용 방법]`을 사용하여 Excel에서 여러 기준 : * VAR 함수를 사용하여 Excel에서 샘플 데이터 수의 분산을 계산합니다.
link : / tips-regression-data-analysis-tool [Excel의 회귀 분석]: * 회귀는 Microsoft Excel에서 대량의 데이터를 분석하고 예측 및 예측을 수행하는 데 사용하는 분석 도구입니다.
link : / statistical-formulas-how-to-create-standard-deviation-graph-in-excel [표준 편차 그래프 생성 방법]: 표준 편차는 데이터가 데이터의 평균을 중심으로 클러스터링 된 정도를 나타냅니다.
인기 기사 :
link : / keyboard-formula-shortcuts-50-excel-shortcuts-to-increase-your-productivity [50 Excel 단축키로 생산성 향상]| 작업 속도를 높이십시오. 이 50 개의 바로 가기를 사용하면 Excel에서 더 빠르게 작업 할 수 있습니다.
link : / formulas-and-functions-introduction-of-vlookup-function [Excel의 VLOOKUP 함수]| 이것은 다른 범위와 시트에서 값을 조회하는 데 사용되는 Excel의 가장 많이 사용되고 인기있는 기능 중 하나입니다. link : / tips-countif-in-microsoft-excel [Excel 2016의 COUNTIF]| 이 놀라운 기능을 사용하여 조건으로 값을 계산합니다. 특정 값을 계산하기 위해 데이터를 필터링 할 필요가 없습니다.
Countif 기능은 대시 보드를 준비하는 데 필수적입니다.
link : / excel-formula-and-function-excel-sumif-function [Excel에서 SUMIF 함수 사용 방법]| 이것은 또 다른 대시 보드 필수 기능입니다. 이를 통해 특정 조건에 대한 값을 합산 할 수 있습니다.