어떻게 Excel에서 NORM.S.DIST 기능을 사용하는
이 기사에서는 Excel에서 NORM.S.DIST 함수를 사용하는 방법을 배웁니다.
정규 누적 분포 란 무엇입니까?
정규 누적 분포는 실수 값 랜덤 변수에 대한 연속 확률 분포 유형입니다. 확률 밀도 함수의 일반적인 형태는 다음과 같이 주어진다.
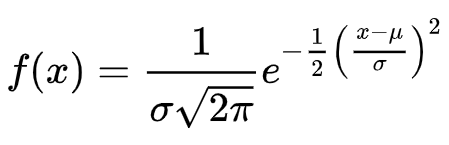
이 값을 기본적으로 Z 값이라고합니다. 계산할 주어진 수학 공식은 매우 복잡합니다. 따라서`link : / statistical-formulas-how-to-use-excel-normdist-function [NORM.DIST Function]`을 사용하여 데이터 세트에 대해 주어진 특정 평균과 표준 편차의 정규 누적 분포를 계산할 수 있습니다. `link : / statistical-formulas-how-to-use-excel-norm-inv-function [NORM.INV Function]`을 사용하여 정규 누적 분포의 역을 계산합니다.
표준 정규 누적 분포는 평균 () = 0 및 표준 편차 () = 1 인 정규 누적 분포의 특수한 경우입니다. 표준 정규 누적 분포의 일반적인 형식은 다음과 같이 지정됩니다.
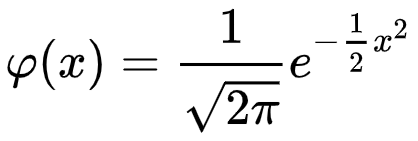
Excel의`link : / statistical-formulas-how-to-use-excel-normdist-function [NORM.DIST Function]`내에서 평균 = 0 및 표준 편차 = 1을 사용하여 표준 정규 누적 분포를 계산할 수 있습니다. 함수가 의존하는 유일한 변수는 x 값 또는 z * 값입니다.
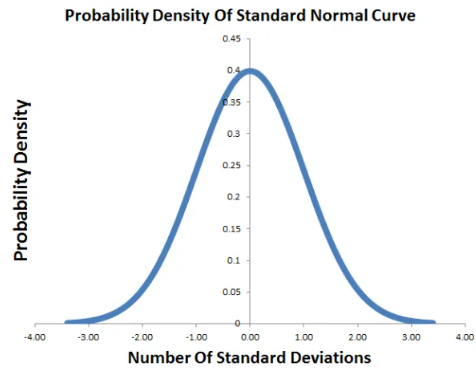
표준 정규 분포 곡선 플롯
표준 정규 분포의 평균은 0이고 표준 편차는 1입니다. 따라서 표준 정규 누적 분포에 대한 확률 밀도 대 표준 편차 곡선은 아래와 같습니다.
위에서 언급 한 수학 공식은 공식을 현명하게 입력하기에는 매우 복잡하므로 Excel은 기본 공식을 제공했습니다. 이제 Excel에서 NORM.S.DIST 함수를 사용하여 누적 분포 또는 확률 질량 분포에 대한 표준 정규 확률을 계산하는 방법을 알아 보겠습니다.
Excel의 NORM.S.DIST 함수
이 함수는 수학 공식과 동일한 작업을 수행합니다. 함수는 x 또는 z 값을 인수로 취하고 결과 pdf 또는 cdf의 유형을 정의하는 누적 인수를 취합니다. 아래의 인수에 대해 더 많이 이해합시다
NORM.S.DIST 함수 구문 :
|
=NORM.S.DIST(x,cumulative) |
x : 분포를 원하는 값 누적 : 함수의 형태를 결정하는 논리 값. cumulative가 TRUE이면 NORM.S.DIST는 누적 분포 함수를 반환합니다. FALSE이면 확률 질량 함수를 반환합니다.
예 :
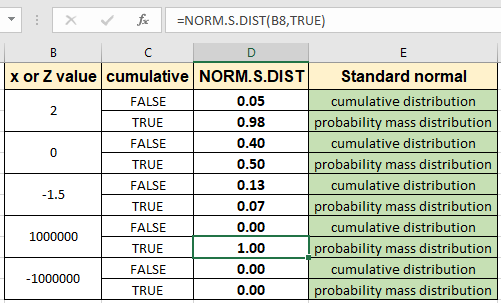
이 모든 것들은 이해하기 어려울 수 있습니다. 예제를 사용하여 함수를 사용하는 방법을 이해합시다. 여기서 우리는 몇 가지 x 값을 취하고 다른 분포 유형을 배웁니다. 먼저 기본 평균 = 0이고 표준 편차 = 1 인 표준 정규 분포에 대해 z 값 2를 갖는 누적 분포를 평가합니다
공식 사용 :
|
=NORM.S.DIST(B2, FALSE) |
또는
|
=NORM.S.DIST(B2, 0) |
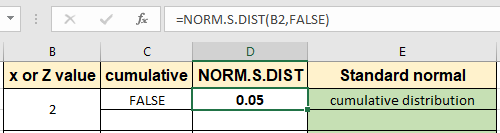
2에 해당하는 확률 값은 표준 정규 분포 데이터 세트에 대해 0.05로 나옵니다. 이제 아래와 같이 동일한 z 값에 대한 확률 질량 분포 확률을 추출합니다.
공식 사용 :
|
=NORM.S.DIST(B2, TRUE) |
또는
|
=NORM.S.DIST(B2, 1) |
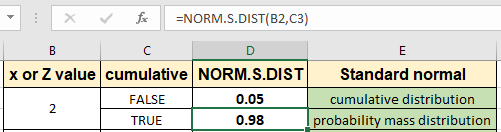
보시다시피 이것에 대한 확률은 이전 값보다 훨씬 높습니다. 서로 다른 z 값에 대해 두 값을 모두 검사 할 수 있습니다. Ctrl + D 단축키를 사용하거나 셀 오른쪽 하단에서 아래로 드래그하여 수식을 다른 셀에 복사하면됩니다.
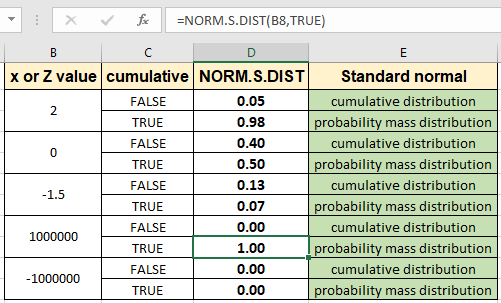
위의 이미지와 같이 결과의 차이를 볼 수 있습니다.
당신은 복잡한 공식을 얼마나 쉽게 엑셀로 만들 었는지 알았습니다. 평균 = 0 및 표준 편차 = 1을 배치 한 NORM.DIST 함수를 사용하여 동일한 결과를 얻을 수 있습니다. 또한 NORM.S.INV 함수를 사용하여 표준 정규 누적 분포의 역을 찾을 수 있습니다.
다음은 Excel의 NORM.S.DIST 함수를 사용하는 모든 관찰 메모입니다
참고 :
-
이 함수는 z 값을 숫자로만 사용할 수 있습니다. 숫자가 아닌 값은 #VALUE! 오류.
-
이 함수는 부울 값 0과 1을 사용하거나 부울 TRUE 및 FALSE 값을 사용하여 누적 분포 및 확률 질량 분포로 전환 할 수 있습니다.
-
Z 또는 x 값은 위의 예와 같이 셀 참조를 사용하거나 직접 지정할 수 있습니다.
Excel에서 NORM.S.DIST 함수를 사용하는 방법에 대한이 기사가 설명이되기를 바랍니다. 여기에서 통계 공식 및 관련 Excel 함수에 대한 더 많은 기사를 찾아보십시오. 블로그가 마음에 들면 Facebook에서 친구들과 공유하세요. 또한 Twitter와 Facebook에서 우리를 팔로우 할 수 있습니다. 우리는 여러분의 의견을 듣고 싶습니다. 우리가 작업을 개선, 보완 또는 혁신하고 여러분을 위해 개선 할 수있는 방법을 알려주십시오. [email protected]로 이메일을 보내주십시오.
관련 기사 :
link : / statistical-formulas-how-to-use-excel-normdist-function [Excel NORM.DIST 함수 사용 방법]: NORMDIST 함수를 사용하여 미리 지정된 값에 대한 정규 누적 분포에 대한 Z 점수를 계산합니다. 뛰어나다.
link : / statistical-formulas-how-to-use-excel-norm-inv-function [Excel NORM.INV 함수 사용 방법]: 미리 지정된 확률에 대한 정규 누적 분포에 대한 Z 점수의 역 계산 Excel에서 NORM.INV 함수를 사용하여 값.
link : / excel-financial-formulas-how-to-calculate-standard-deviation-in-excel [Excel에서 표준 편차를 계산하는 방법]: * 표준 편차를 계산하기 위해 Excel에는 다양한 기능이 있습니다. 표준 편차는 분산 값의 제곱근이지만 분산보다 데이터 세트에 대해 더 많이 알려줍니다.
link : / tips-regression-data-analysis-tool [Regressions Analysis in Excel]: Regression은 Microsoft Excel에서 대량의 데이터를 분석하고 예측 및 예측을 수행하는 데 사용하는 분석 도구입니다. link : / statistical-formulas-how-to-create-standard-deviation-graph-in-excel [표준 편차 그래프 생성 방법]: 표준 편차는 데이터의 평균을 중심으로 클러스터링 된 데이터의 양을 나타냅니다. 여기에서 표준 편차 그래프를 만드는 방법을 알아보세요.
link : / statistical-formulas-excel-var-function [Excel에서 VAR 함수 사용 방법]: Excel에서 VAR 함수를 사용하여 Excel에서 샘플 데이터 세트의 분산을 계산합니다.
인기 기사 :
link : / tips-if-condition-in-excel [Excel에서 IF 함수 사용 방법]: Excel의 IF 문은 조건을 확인하고 조건이 TRUE 인 경우 특정 값을 반환하거나 FALSE 인 경우 다른 특정 값을 반환합니다. .
link : / formulas-and-functions-introduction-of-vlookup-function [Excel에서 VLOOKUP 함수 사용 방법]: 다양한 범위의 값을 조회하는 데 사용되는 Excel에서 가장 많이 사용되는 인기 함수 중 하나입니다. 및 시트. link : / excel-formula-and-function-excel-sumif-function [Excel에서 SUMIF 함수 사용 방법]: 대시 보드의 또 다른 필수 기능입니다. 이를 통해 특정 조건에 대한 값을 합산 할 수 있습니다.
link : / tips-countif-in-microsoft-excel [Excel에서 COUNTIF 함수 사용 방법]:이 놀라운 함수를 사용하여 조건으로 값을 계산합니다. 특정 값을 계산하기 위해 데이터를 필터링 할 필요가 없습니다. Countif 기능은 대시 보드를 준비하는 데 필수적입니다.