Microsoft Excel에서 F-테스트
Array1과 array2 및 F- 검정은이 함수를 사용할지 여부를 결정하기 위해 두 표본 분산을 미분하는 양측 가능성에서 표현 적으로 다르지 않습니다. 이 학교가 다양한 수준의 시험 점수를 가지고 있는지 여부.
F-Test 구문 = FTEST (arrray1, array2)
Array1은 데이터의 첫 번째 배열 또는 범위입니다.
Array2는 두 번째 배열 또는 데이터 범위입니다.
이 도구에 액세스하려면 데이터 탭을 클릭하고 분석 그룹에서 데이터 분석을 클릭하십시오. 데이터 분석 명령을 사용할 수없는 경우 분석 도구를로드해야합니다.
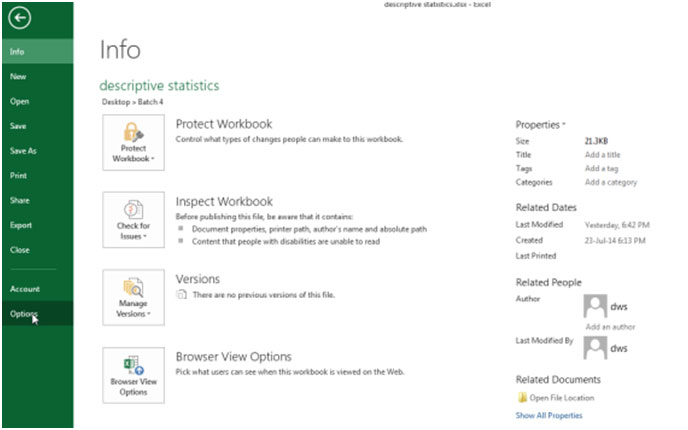
분석 도구를로드하고 활성화하려면 아래 언급 된 단계를 따르십시오 .- * 파일 탭을 클릭하고 옵션을 클릭 한 다음 INS 카테고리 추가를 클릭합니다.
-
관리 상자에서 분석 도구를 선택한 다음 이동 버튼을 클릭합니다.
-
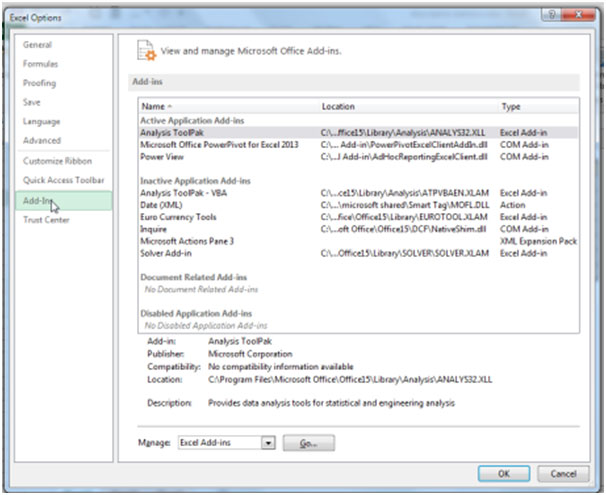
추가 기능 대화 상자에서 분석 도구 확인란을 선택한 다음 확인을 클릭합니다.
-
사용 가능한 추가 기능 상자에 Analysis Toolpak이 표시되지 않으면 찾아보기를 클릭하여 찾습니다.
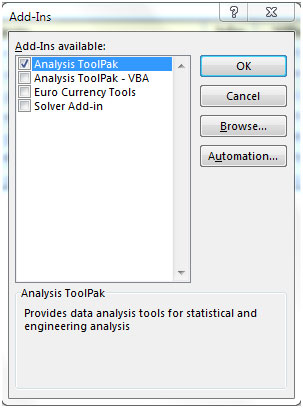
주제로 돌아가서 F-Test Two-Sample for Variances를 통해 데이터를 분석해 보겠습니다.
A2 : B12 범위에있는 2 개 그룹의 비고 점수 데이터가 있습니다. A 열에는 그룹 1의 데이터가 있고 B 열에는 2 ^ nd ^ 그룹의 데이터가 있습니다.
분산에 대해 F- 검정 2- 표본을 사용하려면 아래 언급 된 단계를 따르십시오.-* 데이터 탭으로 이동합니다.
-
분석 그룹에서 데이터 분석을 클릭합니다.

-
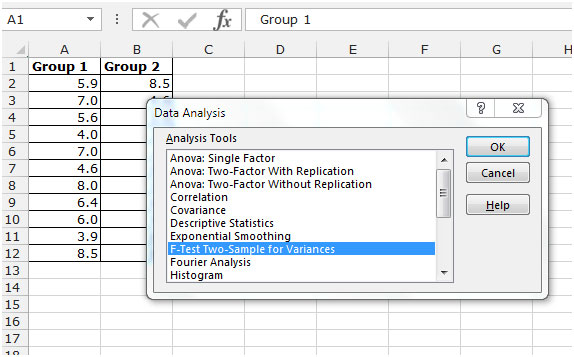
데이터 분석 대화 상자가 나타납니다.
-
분석 도구 드롭 다운 메뉴에서 F-Test Two-Sample for Variances를 클릭하고 확인을 클릭합니다.
-
F-Test Two-Sample for Variances 대화 상자가 나타납니다.
-
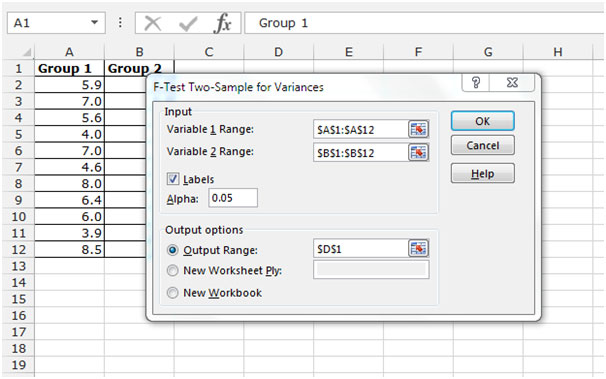
입력 범위를 클릭합니다. 1 ^ st ^ 변수 범위 A1 : A12를 선택하고 2 ^ nd ^ 변수 범위 B1 : B12를 선택합니다.
-
결과에서 헤더를 가져 오려면 첫 번째 행의 레이블을 선택하십시오.
-
출력 범위를 선택하고 요약을 표시하려는 셀을 선택하십시오.
-
확인을 클릭하십시오.
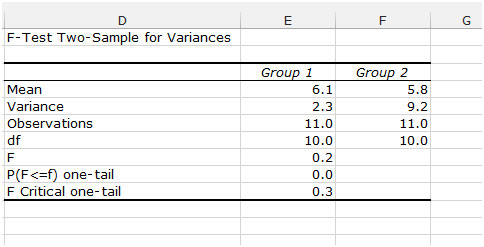
중요 : 변수 1의 분산이 변수 2의 분산보다 큰지 확인하십시오. 이것은 2.3 <9.2의 경우입니다. 그렇지 않은 경우 데이터를 교환하십시오. 결과적으로 Excel은 Variance 1과 Variance 2의 비율 (F = 2.3 / 9.2 = 0.25) 인 올바른 F 값을 계산합니다.