어떻게 엑셀 COVARIANCE.S 기능을 사용하는 방법?
공분산이란 무엇입니까?
`link : / statistical-formulas-how-to-use-excel-covariance-p [COVERAINCE.P function]`에서 배운 것처럼 두 무작위 변수 간의 관계 측정을 공분산이라고합니다. 이름에서 알 수 있듯이 두 변수의 공분산은 다른 변수가 변경 될 때 한 변수가 어떻게 변하는 지 알려줍니다. 공분산은 한 변수의 다른 변수에 대한 종속성을 정의하지 않습니다. 공분산 계산에는 두 가지 유형이 있습니다.
첫 번째는 모집단의 공분산이고 다른 하나는 표본의 공분산입니다. 이 기사에서는 Excel에서 샘플의 공분산을 계산하는 방법을 알아 봅니다.
공분산 값은 음수 또는 양수 값일 수 있습니다. 음수 값은 두 변수가 반대 방향으로 이동 함을 의미합니다. 그리고, 당신은 그것을 맞혔습니다. 양의 공분산은 두 변수가 같은 방향으로 움직인다는 것을 의미합니다.
‘link : / statistical-formulas-how-to-find-correlation-coefficient-in-excel [상관 계수]’처럼 들릴 수 있지만 다릅니다. 우리는 결국 그것에 대해 이야기 할 것입니다.
Excel에서 샘플의 공분산을 찾는 방법은 무엇입니까?
Excel은 COVARIANCE.S를 제공하여 샘플 데이터의 공분산을 쉽게 계산합니다. Excel 2010에서 도입 된 이후로 널리 사용되고 있습니다. Excel 2016에서 사용하고 있습니다.`link : / statistical-formulas-how-to-use-excel-covariance-p [COVARIANCE.P]`라는 다른 버전의 메서드가 있습니다.이 메서드는 공분산을 계산하는 데 사용됩니다. 인구.
COVARIANCE.S의 구문 :
|
=COVARIANCE.S(array1,array2) |
Array1 : * 첫 번째 변수의 값입니다.
Array2 : * 두 번째 변수의 값입니다.
참고 : *이 배열은 임의의 순서로 배치 할 수 있습니다. 두 배열의 길이는 동일해야합니다. 두 배열의 길이가 서로 다른 경우 Excel은 # N / A 오류를 표시합니다.
이제 공분산에 대해 알았으므로 더 명확하게 만드는 예를 들어 보겠습니다.
예 : Excel에서 모집단의 공분산 계산
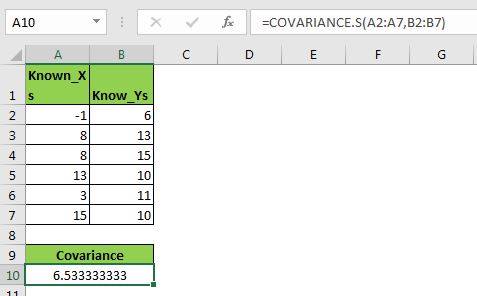
여기에 샘플 데이터 세트가 있습니다. A2 : A7 범위에는 변수 X가 있고 B2 : B7 범위에는 또 다른 변수 Y가 있습니다. 이제이 데이터의 공분산을 계산하고이 두 변수가 서로 어떻게 영향을 미치는지 살펴 보겠습니다.
 Let’s use the Excel COVARAINCE.S function:
Let’s use the Excel COVARAINCE.S function:
|
=COVARIANCE.S(A2:A7,B2:B7) |
6.533333333의 값을 반환합니다.
공분산 해석
우리가 얻은 공분산 값은 양의 값입니다. X와 Y가 같은 방향으로 움직인다는 것을 알려줍니다. 즉, X가 증가하면 Y가 증가하고 그 반대의 경우도 마찬가지입니다. 공분산이 음수이면 그 반대가됩니다.
COVARIANCE.S는 어떻게 계산됩니까?
음, 샘플의 공분산을 계산하는 수학 공식은 다음과 같습니다.
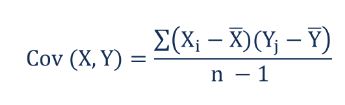
여기서 X ~ i ~는 변수 X의 값입니다. 여기서 X 막대는 변수 X의 샘플 평균입니다.
Y ~ i ~는 변수 Y의 값입니다. 여기서 Y 막대는 변수 Y의 샘플 평균입니다.
n은 관측치의 수입니다. 분모에서 1을 뺍니다. 샘플 데이터 일 뿐이며 전체 모집단의 데이터를 캡처 한 것이기 때문에 안전한 편입니다. 이것이 항상 모집단의 공분산보다 큰 이유입니다.
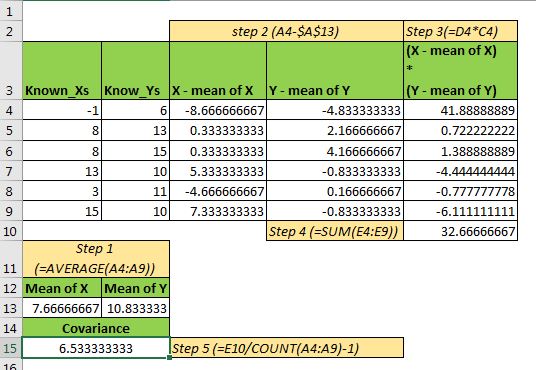
Excel에서 샘플의 공분산을 수동으로 계산하려고하면 이렇게 할 수 있습니다.
-
먼저 셀에있는 X 및 Y 변수의`link : / statistical-formulas-how-to-calculate-mean-in-excel [산술 평균 계산]`입니다. AVERAGE 함수를 사용할 수 있습니다.
|
= |
-
X의 각 값에서 X의 평균을 뺍니다. Y에 대해서도 동일하게 수행합니다.
|
=A4-$A$13 |
-
이제 여러 X- 평균 X 및 Y- 평균 Y 범위. 위의 이미지를 참조하십시오.
|
=D4*C4 |
-
이제 곱셈으로 얻은 값을 더하십시오.
|
=SUM(E4:E9) |
-
마지막으로 얻은 합계를 여러 관측치로 나눕니다. 우리의 경우에는 6입니다.
|
=E10/( |
우리가 얻은 숫자는 6.533333333이며 Excel COVARIANCE.S 함수에서 얻은 것과 정확히 동일합니다.
공분산과 상관 계수의 차이
첫 번째이자 주요 차이점은 공식입니다. `link : / statistical-formulas-how-to-find-correlation-coefficient-in-excel [상관 계수]`는 공분산을 Xs와 Y의 표준 편차 곱으로 나누어 계산합니다.
공분산은 두 개의 랜덤 변수가 같은 방향으로 이동하는지 다른 방향으로 이동하는지 여부를 알려줍니다. 두 변수 간의 관계의 강도를 알려주지 않습니다. 상관 관계는 -100 %에서 100 % 범위의 두 변수 간의 관계 강도를 보여줍니다.
예 여러분, 이것이 Excel에서 COVARIANCE.P를 사용하는 방법입니다. 이 기사에서 우리는 COVARIANCE.P 함수에 대해 배웠을뿐만 아니라 수동으로 계산하는 방법과 파생하는 방법도 배웠습니다. 내가 충분히 설명했으면 좋겠다. 이 정적 함수 또는 Excel의 다른 정적 함수에 대해 의문이있는 경우 아래 주석 섹션에 주석을 추가하십시오.
관련 기사 :
link : / statistical-formulas-how-to-find-correlation-coefficient-in-excel [Excel에서 상관 계수를 찾는 방법]
link : / statistical-formulas-calculate-intercept-in-excel [Excel에서 INTERCEPT 계산]
link : / statistical-formulas-calculating-slope-in-excel [Excel에서 SLOPE 계산]
link : / statistical-formulas-how-to-use-excel-normdist-function [Excel NORMDIST 함수 사용 방법]
link : / tips-regression-data-analysis-tool [2010 년 엑셀 회귀]
link : / tips-how-to-create-a-pareto-chart-in-microsoft-excel [파레토 차트 및 분석]
인기 기사 :
link : / keyboard-formula-shortcuts-50-excel-shortcuts-to-increase-your-productivity [50 Excel 단축키로 생산성 향상]
link : / formulas-and-functions-introduction-of-vlookup-function [Excel의 VLOOKUP 함수]
link : / tips-countif-in-microsoft-excel [Excel 2016의 COUNTIF]
link : / excel-formula-and-function-excel-sumif-function [Excel에서 SUMIF 함수 사용 방법]